[MasterThe Coding Interview]Algorithms:Searching + BFS + DFS
本篇為MasterThe Coding Interview教學影片筆記文
搜尋存在各種地方,google的搜尋引擎、蝦皮的搜尋商品等,任何有規模的網站都會用到搜尋功能,以下是這次要介紹的搜尋演算法:
Linear Search
適用於list的資料,從頭到尾一個一個的查看,是一個O(n)的演算法,因為最後的情況是要找的東西在最後面。
1 | var beasts = ['Centaur' , 'Godzilla' , 'Mosura' , 'Minotaur' , 'Hydra' , 'Nessie']; |
Binary Search
適用已經sort過的資料,透過不斷的從中間分割來找到目標,時間複雜度是O(logn)。
1 | // 9 |
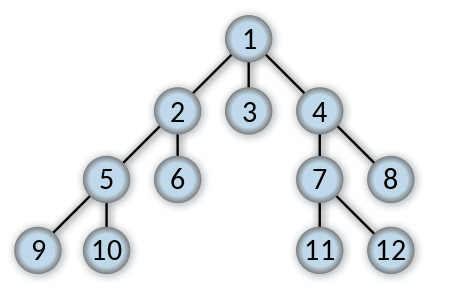
Breadth First Search
從第一層開始一層一層的往下開始找,一定是找完當前這一層才會往下一層走。
1 | // 9 |
| 優點 | 缺點 |
|---|---|
| Shortest Path | More Memory |
| Closer Nodes |
Depth First Search
從第一個分支開始往最深處找,直到沒辦法再深才會換到下一個分支。DFS 主要有三種方式,前序遍歷 (Preorder)、中序遍歷 (Inorder)、後序遍歷 (Postorder),跟BFS不一樣,不需要一個queue來儲存所有還未找尋的node,只需要儲存分支上的Node即可。
1 | // 9 |
| 優點 | 缺點 |
|---|---|
| Less Memory | Can Get Slow |
| Does Path Exist |
BFS vs DFS
- If you know a solution is not far from the root of the tree → BFS(適合搜尋最近的點)
- If the tree is very deep and solutions are rare → BFS(因為樹太深了,DFS會耗費太多時間)
- If the tree is very wide → DFS(因為樹太深了,BFS會耗費太多memory)
- If solutions are frequent but located deep in the tree → DFS
- Determining whether a path exists between two nodes →DFS
- Finding the shortest path → BFS
BFS and DFS in Graph
其實圖跟樹的方法都一樣,只是可以更明顯的看出兩者的差異,如果圖中的一個node連結很多很多node,那我們用BFS就有可能會耗費太多memory,相反的,如果圖的深度很深,用DFS的時候因為是用resursive實作,會造成太多的call stack,耗費太多memory和時間。
但是!當我們圖的路徑有權重的時候,找出最短路徑就不能使用BFS來實作,必須用另外兩種特殊的演算法來實作,Dijkstra和Bellman-Ford,兩個都是最短路徑的演算法,Bellman-Ford的效率比Dijkstra好,而且Bellman-Ford可以有負數,Dijkstra不行,但值得一提的是Bellman-Ford的worst case有可能到O(n^2),所以當路徑的權重沒有負數的時候,我們仍然會使用Dijkstra。
補充:Finding The Shortest Path, With A Little Help From Dijkstra